Python: Text to Speech
Text-to-Speech (TTS) is a kind of speech synthesis which converts typed text into audible human-like voice.
There are several speech synthesizers that can be used with Python. In this tutorial, we take a look at three of them: pyttsx, Google Text-to-Speech (gTTS) and Amazon Polly.

We first install pip, the package installer for Python.
$ curl -O https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
If you have already installed it, upgrade it.
$ sudo pip install --upgrade pip
We will start with the tutorial on pyttsx, a Text-to-Speech (TTS) conversion library compatible with both Python 2 and 3. The best thing about pyttsx is that it works offline without any kind of delay. Install it via pip.
$ sudo pip install pyttsx3
By default, the pyttsx3 library loads the best driver available in an operating system: nsss on Mac, sapi5 on Windows and espeak on Linux and any other platform.
Import the installed pyttsx3 into your program.
Here is the basic program which shows how to use it.
import pyttsx3
engine = pyttsx3.init()
engine.say('Hello, World!')
engine.runAndWait()
pyttsx3 Female Voices
Now let us change the voice in pyttsx3 from male to female. If you wish for a female voice, pick voices[10], voices[17] from the voices property of the engine. Of course, I have picked the accents which are easier for me to make out.
import pyttsx3
engine = pyttsx3.init()
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[17].id)
engine.say('Hello, World!')
engine.runAndWait()
You can actually loop through all the available voices and pick the index of the voice you desire.
import pyttsx3
engine = pyttsx3.init()
voices = engine.getProperty('voices')
for voice in voices:
engine.setProperty('voice', voice.id)
engine.say('Here we go round the mulberry bush.')
engine.runAndWait()
Google Text to Speech (gTTS)
Now, Google also has developed an application to read text on screen for its Android operating system. It was first released on November 6, 2013.

It has a library and CLI tool in Python called gTTS to interface with the Google Translate text-to-speech API.
We first install gTTS via pip.
sudo pip install gTTS
gTTS creates an mp3 file from spoken text via the Google Text-to-Speech API.
We will install mpg321 to play these created mp3 files from the command-line.
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" < /dev/null 2> /dev/null
brew install mpg321
Using the gtts-cli, we read the text 'Hello, World!' and output it as an mp3 file.
gtts-cli 'Hello, World!' --output hello.mp3
We now start the Python interactive shell known as the Python Shell
$ python3
You will see the prompt consisting of three greater-than signs (>>>), which is known as the Python REPL prompt.
Import the os module and play the created hello.mp3 file.
>>> import os
>>> os.system("mpg321 hello.mp3")
Putting it all together in a single .py file
from gtts import gTTS
import os
tts = gTTS(text='Hello, World!', lang='en')
tts.save("hello.mp3")
os.system("mpg321 hello.mp3")
The created hello.mp3 file is saved in the very location where your Python program is.
gTTS supports quite a number of languages. You will find the list here.
The below line creates an mp3 file which reads the text "你好" in Chinese.
gtts-cli "你好" -l 'zh-cn' -o hello.mp3 --slow
The below program creates an mp3 file out of text "안녕하세요" in Korean and plays it.
from gtts import gTTS
import os
tts = gTTS(text='안녕하세요', lang='ko')
tts.save("hello.mp3")
os.system("mpg321 hello.mp3")
Amazon Polly
Amazon also has a cloud-based text-to-speech service called Amazon Polly.
If you have an AWS account, you can access and try out the Amazon Polly console here:
https://console.aws.amazon.com/polly/
The interface looks as follows.
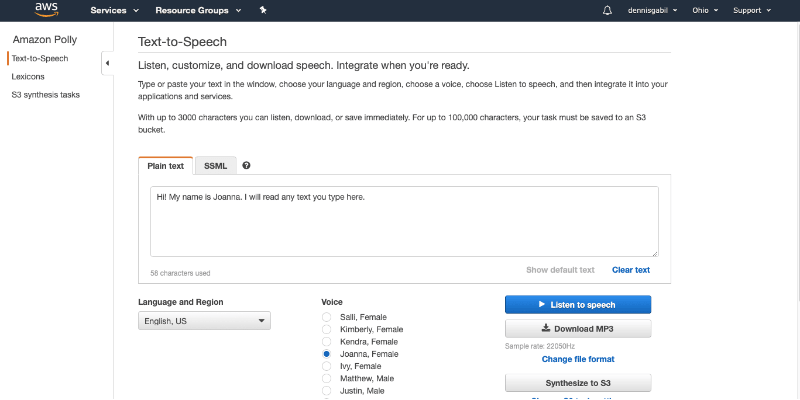
There is a Language and Region dropdown to choose the desired language from and several male and female voices to pick too. Pressing the Listen to speech button reads out the text typed into the text box. Also, the speech is available to download in several formats like MP3, OGG, PCM and Speech Marks.
Now to use Polly in a Python program, we need an SDK. The AWS SDK for Python is known as Boto.
We first install it.
pip install boto3
Now to initiate a boto session, we are going to need two more additional ingredients: Access Key ID and the Secret Access Key.
Login to your AWS account and expand the dropdown menu next to your user name, located on the top right of the page. Next select My Security Credentials from the menu.

A pop-up appears. Click on the Continue to Security Credentials button on the left.
Expand the Access keys tab and click on the Create New Access Key button.
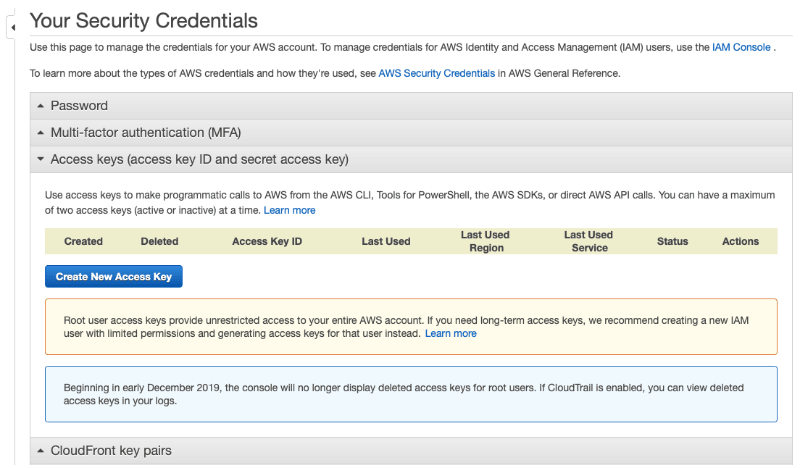
As soon as you click on the Create New Access Key button, it auto creates the two access keys: Access Key ID, a 20-digit hex number, and Secret Access Key, another 40-digit hex number.
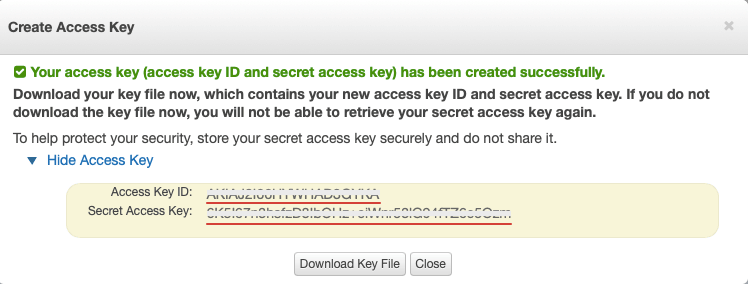
Now we have the two keys, here is the basic Python code which reads a given block of text, convert it into mp3 and play it with mpg321.
import boto3
import os
polly_client = boto3.Session(
aws_access_key_id='********************',
aws_secret_access_key='****************************************',
region_name='us-west-2').client('polly')
response = polly_client.synthesize_speech(VoiceId='Joanna',
OutputFormat='mp3',
Text = 'There is a river called the river of no return.')
file = open('speech.mp3', 'wb')
file.write(response['AudioStream'].read())
file.close()
os.system("mpg321 speech.mp3")
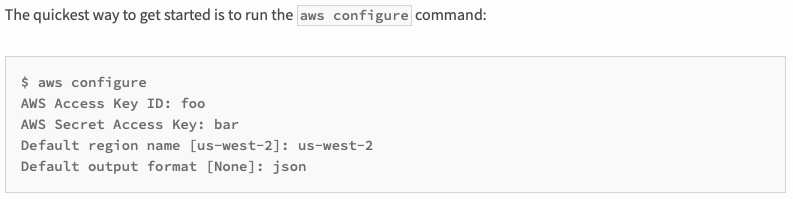
There is also another way to configure Access Key ID and the Secret Access Key. You can install awscli, the universal command-line environment for AWS,
pip install awscli
and configure them by typing the following command.
aws configure